

Those of you who regularly follow the site may have thought things were quiet lately. Behind the scenes, I have been working hard on something I have wanted to do for about 18 months, and that is to convert QuickHash for use with SQLite.
SQLite, as you probably know, is a very fast and powerful (but also fairly simple) database technology. It gives you all the benefits and power of a traditional relational database like MySQL, Firebird, Oracle and so on but without the enormous server overheads, user connectivity issues and, in some cases, licensing issues. With SQLite, developers can code their programs to create and populate a local database with tables, fields and rows, and have their program act as the front end for that database. What this means is that if you want to quickly re-list your results based on a certain criteria, and have the results listed in, literally, the blink of an eye, you can do. I tested it on 70K files the other day, and when I asked it to list just the duplicates it did in, literally, the blink of my eye. I thought for a moment it had not done anything until I realised what it had done in just a few milliseconds.
SQLite is like a hard working member of staff on a team….he gets things done without fuss and drama and without over complicating things. He's the bricky who lays a thousands bricks before lunch, with every brick perfectly straight and the shade of cement always the same.
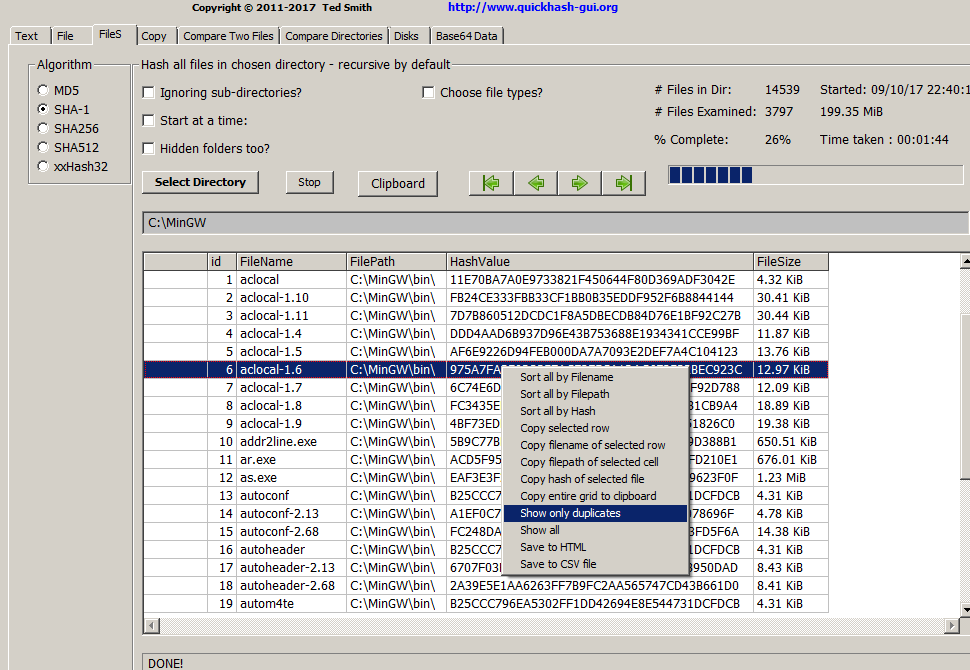
Quickhash is used by so many people and industries these days, it is time (and has been time for a while) for me to progress it beyond the basic design it started out with and move it to a more flexible and powerful database model where it can more easily cope with millions of files but still retain that portability and flexibility that QuickHash has become famous for; and SQLite is the solution for that. As you can see in the screenshot, taken from an early alpha v3.0.0 of QuickHash, you can see the myriad of options that I have been able to incorporate already and I can do so with a simple right click option. This also means much of the clutter has been removed from the interface.
In addition, the user now has an easy to use navigation bar, to move to different parts of the display grid. The output is better and more neatly presented, especially the HTML output. And user can select all kinds of clipboarding options besides just the entire grid as was the general choice before.
I may one day also consider the more serious database systems like MySQL and Firebird so that big data types can actually store these values in the database long term, but that will only be once I am confident with coding SQLite, which is fairly new to me generally.
It's nowhere near ready for release yet. So far over the last 4 weeks or so I have only incorporated SQLite for the "FileS" and "Copy" tabs only, and I still have the "Compare Two Directories" tab to do, which won't be straight forward. And after that, I need to test it more and only then will I release a beta for user testing. I'll want people to try it out by running it over large data volumes, to check that the optimisations I am hoping for actually do exist in real life!!
But progress has been steady and it doesn't look like I'm going to give up on the idea. So I thought I'd mention it. Watch this space, and, if you're a developer, the "v3Branch" branch of the github repository.

Leave a Reply