

As I reported a few weeks ago, I’ve been working hard as often as I can on v3.0.0 of QuickHash that now utilises SQLite technology. It’s been a massive task – much bigger than I first thought. It’s taken me nearly two months of late nights and weekend work to get the beta nearly ready for release.
It’s been a major re-write and lots of new options have been added by means of right click menus and so on, which SQLite has allowed more easily than earlier versions. Simply things like the ability to sort on individual columns but then be able to selectively copy single cell values, like filename, or path. Searching for duplicate entries, and more, often in less than a second for even really big data volumes.
I’m still testing it, to avoid releasing a buggy new version. One of the big hurdles has been making it cross platform with regard to ensuring that SQLite will work on all three versions of the program. SQLite works everywhere of course, but the programmer has to be able to call the correct library for the operating system that his program finds itself running on. As of 21st Nov, I seem to have managed that step, and the latest Git commit of v3Branch includes it. I’ve managed to run the program successfully on all of my Windows, Linux and OSX systems so I am hopeful others will be able to, too.
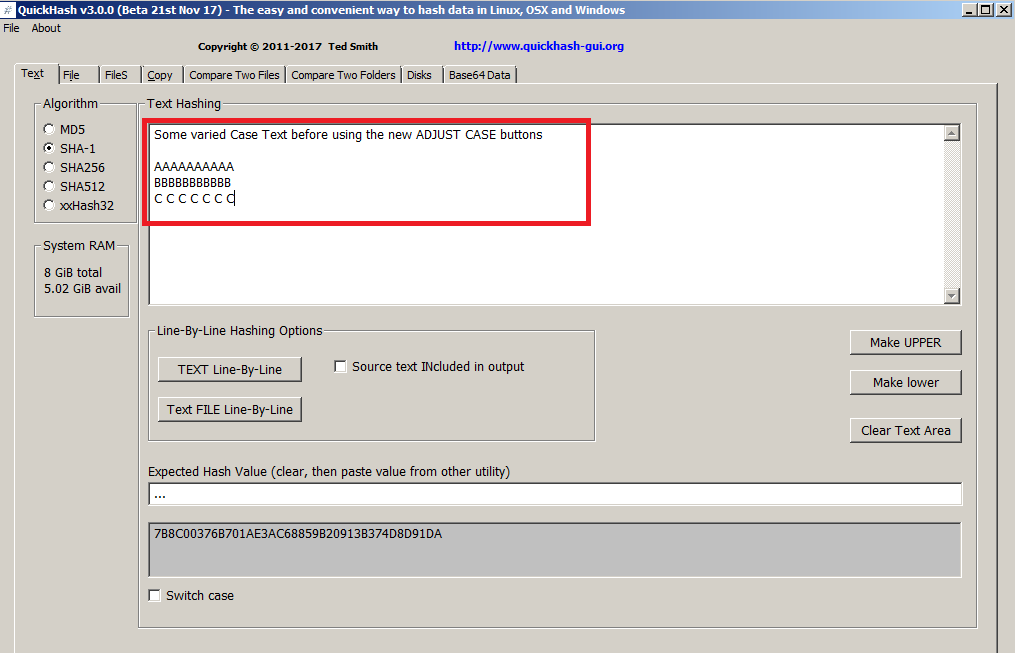
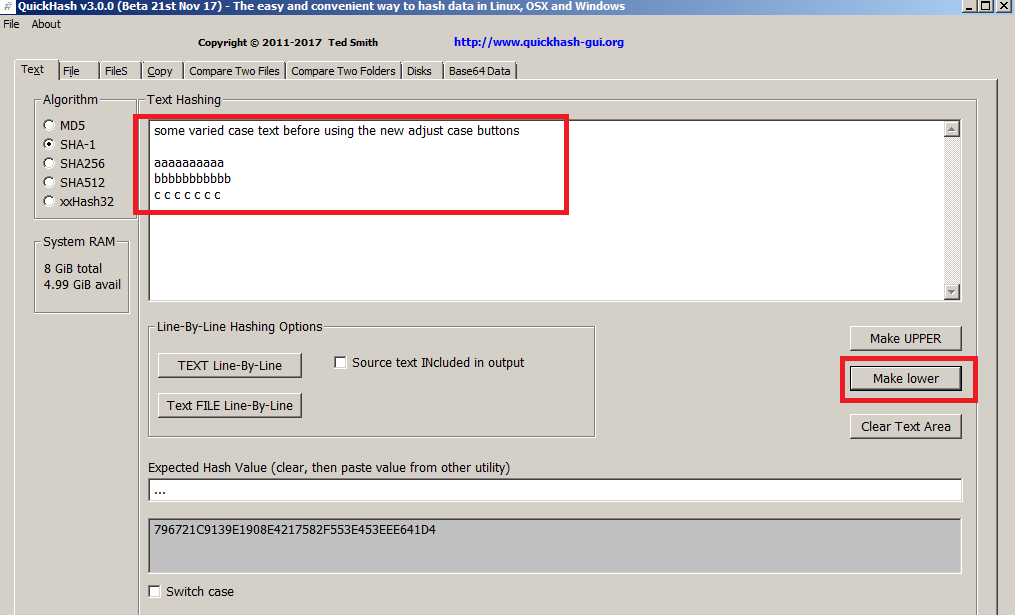
Lots of other new features\changes as well….lots around the text tab in fact. Many users are using QuickHash in the marketting arenas for generating hashes of e-mail lists and so on. One user contacted me recently to report using it to hash 400K addresses, and QuickHash managed it in almost the blink of an eye. So that was nice to hear. The user contributed several more ideas, some of which are included in v3.0.0. It’s become apparant that users want to use QuickHash as a “one stop shop” to both sanitise and prepare their data as was as hashing it (although I always formerly take the stance that you should use Excel or whatever to ensure your text data is ready for hashing). So case sensitivity has become a big issue. So, to address this demand, now there are buttons to convert the input to uppercase, or convert it to lowercase.
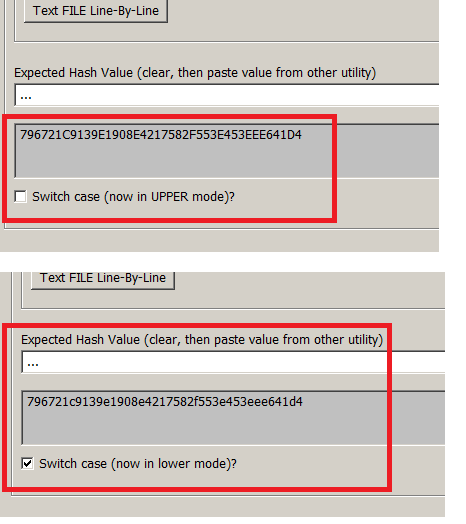
There’s also a case switcher for the generated hash value too. Although it’s UPPER by default, the user can easily switch it now. This was added because many folks needs to generate a hash of a hash! So hashing a hash that is uppercase is different to hashing a lower case hash. So that feature has been added as well.
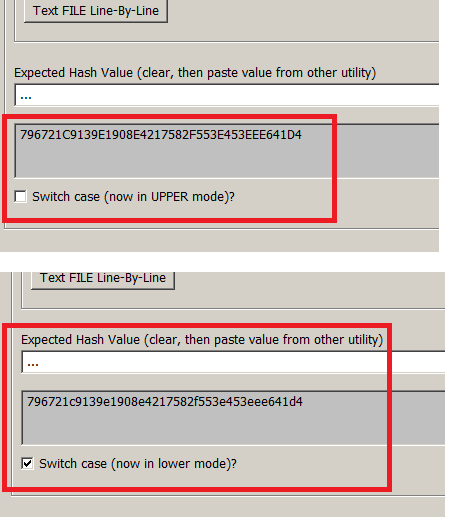
QuickHash v3.0.0 – new hash result case switcher
The “Compare Two Directories” tab has been renamed to “Compare Two Folders” and the entire section has been re-written to utilise hash lists which should make it much faster. As you can see, the interface is much easier on the eye and well structured compared to v2.8.4 of QuickHash.
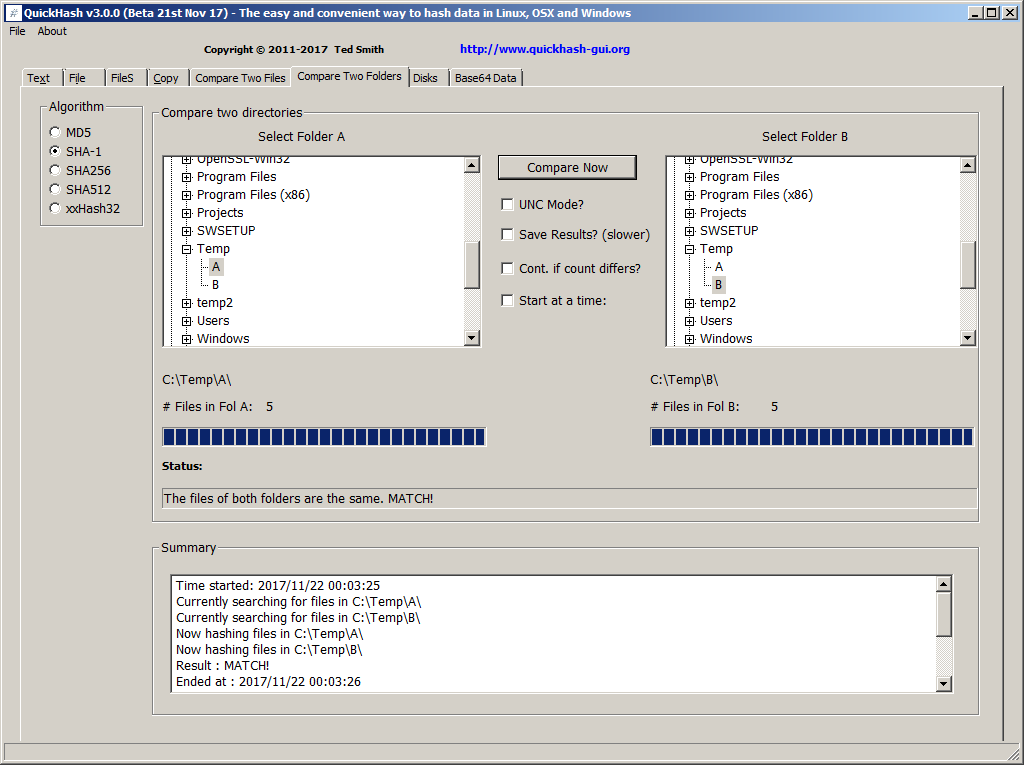
The new Compare Two Folders tab of v3.0.0
There’s loads more I could write about but the CHANGELOG will document all the new features of v3.o.0. I hope to get a beta out soon for general use after a few close friends put it through its paces privately. I don’t want to hype up v3.0.0 and then release something that doesn’t work as it should. That said, with any major overhaul, users should expect a mild issue here and there – it might take a while to iron out the various glitches that are inevitable when so many new features are added to a cross platform tool.
Anyone who is eager\keen to try out and play with a beta of v3.0.0 is welcome to request a copy before more general release by e-mailing me at tedsmith@34.225.163.28

Leave a Reply